Reducing LLM Costs Is Easy — Until Production Starts
Originally published on Dev.to on April 13, 2026.
Read the Dev.to version
A month ago, I wrote about reducing LLM costs using caching.
The idea is simple: don’t send the same or similar request to the model twice.
It works well in demos. It even works well in early testing.
And then production starts.
Production Reality: Where LLM Systems Start Breaking
At first, everything looks under control. Requests are small, traffic is predictable, and caching delivers immediate savings. You see fewer calls to the model and faster responses. It feels like the problem is solved.
But real systems don’t stay simple for long.
Prompts begin to grow. What used to be a short question turns into a long conversation with accumulated context, system instructions, and sometimes entire documents pasted by users. Requests become heavier, slower, and more expensive in ways that caching alone cannot fix.
At the same time, failures start to blur together. A timeout, a malformed request, and an upstream provider error all look the same from the outside. Without clear separation, debugging becomes guesswork, and cost anomalies become difficult to explain.
Then there’s latency. A request times out — but what actually happened? Was the provider slow? Did the request even reach it? Should you retry it or not? Without visibility into upstream behavior, you’re operating blind.
Even semantic caching, which looks almost magical at first, becomes a tuning problem. Similarity thresholds that worked in testing suddenly feel off. Some responses are reused too aggressively, others not at all. Without insight into what the system is actually doing, you’re left adjusting numbers and hoping for the best. This is all similar to how prompts are tuned — but here, the feedback loop is missing.
Finally, the moment that exposes everything: deployment.
You restart the service during traffic, and suddenly there are dropped requests, inconsistent responses, and unpredictable behavior. What worked perfectly in isolation now reveals gaps in lifecycle handling.
The Missing Layer: LLM Systems Have No Traffic Control
What all of this points to is a deeper issue.
LLM applications don’t just need optimization. They need a control layer.
In traditional systems, we never send traffic directly to application logic. There is always a layer in front — something that validates, routes, filters, and observes. Tools like Nginx became essential not because they were convenient, but because they made systems predictable.
LLM systems are now facing the same reality.
From Calling Models to Controlling Requests
When you introduce a control layer in front of LLMs, the perspective changes.
The question is no longer just “how do I call the model?” but “should this request reach the model at all?”
Is it valid? Has it already been answered? What happens if it fails?
Cost optimization becomes a side effect of something bigger: managing traffic properly.
From Caching to Control: What Changed in Real Deployments
This is where the AI Cost Firewall evolved.
It started as a caching layer — combining exact matches in Redis with semantic search in Qdrant. That alone reduced a significant portion of redundant requests.
But real deployments made it clear that caching is only the beginning. The system needed to behave predictably under load, during failures, and across deployments. So the focus shifted.
Readiness and liveness became explicit, separating a healthy process from one that is actually ready to handle traffic. Shutdown behavior was redesigned to drain in-flight requests instead of dropping them. Restarts became controlled events rather than risky moments.
Errors were no longer just errors. They were classified: validation issues, upstream timeouts, provider failures, internal faults — each telling a different story about what went wrong.
Upstream behavior stopped being a black box. Latency became measurable, timeouts became visible, and slow responses could finally be distinguished from real failures.
Semantic caching also became observable. Instead of guessing whether it works, you can now see how many candidates are evaluated, how often thresholds pass or fail, and how long lookups take. What used to feel like a heuristic now becomes something you can tune with confidence.
And perhaps most importantly, the system itself became visible while it runs. You can tell whether it is ready, whether it is shutting down, and how it behaves under real traffic — not just in theory.
At this point, semantic caching stops being a black box.
This is what diagnostics visibility looks like in practice:
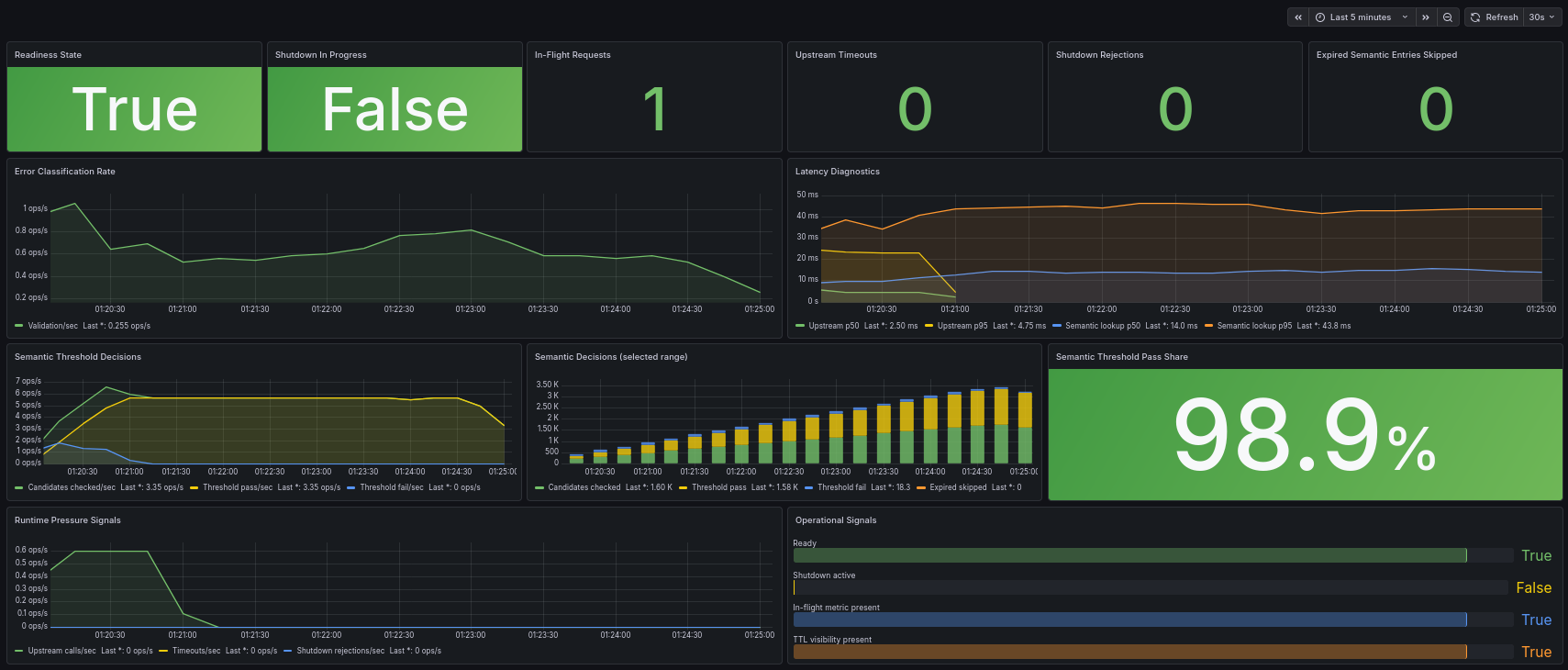
Instead of guessing thresholds, you now have feedback. Instead of assumptions, you have data.
Why Predictability Matters More Than Features
None of these changes are flashy.
They don’t improve model quality or add new capabilities.
But they solve something more fundamental: they make the system predictable.
And without predictability, cost optimization doesn’t hold.
Caching Starts It, Control Makes It Work
Reducing LLM costs is easy when everything is controlled and small.
It becomes difficult when requests grow, failures mix together, and systems need to operate continuously under real conditions.
At that point, the problem is no longer about saving tokens. It’s about understanding and controlling the flow of requests before they ever reach the model.
Caching is where it starts. Control is what makes it work in production.
If you want to experiment with the tool, the AI Cost Firewall project is open-source and designed to run as a drop-in OpenAI-compatible gateway in front of existing applications:
https://github.com/vcal-project/ai-firewall
Built and maintained by the VCAL Project team — feedback and real-world use cases are very welcome.
